




What is disaster recovery (DR)?
Disaster Recovery (DR) is a set of policies, procedures, and tools designed to enable the recovery or continuation of critical technology infrastructure and systems following a natural or human-induced disaster. The aim is to minimize downtime and data loss to ensure business continuity in the face of disruptive events.
DR objectives
Disaster events such as earthquakes, network outrage and human actions such as inadvertent or unauthorized modifications can potentially take down your workload, therefore it is important to set disaster recovery objectives. These objectives guide the development and execution of the disaster recovery strategy. Here are common disaster recovery objectives:
Recovery Time Objective (RTO): This objective defines the maximum acceptable delay between the interruption of service and restoration of service.
Recovery Point Objective (RPO): This object defines the maximum amount of data (measured by time) that can be lost after a recovery from a disaster.
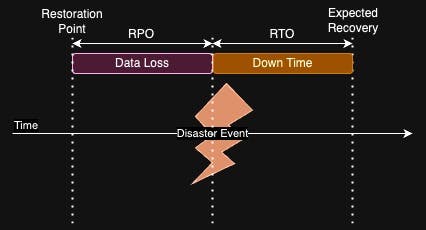
The lower numbers (both RTO and RPO) indicate less downtime and data loss. However, this means that lower RTO and RPO cost more in terms of spend on resources and increase operational complexity. Hence, a company should choose both RTO and RPO objectives that could provide appropriate value for your workload.
DR strategies
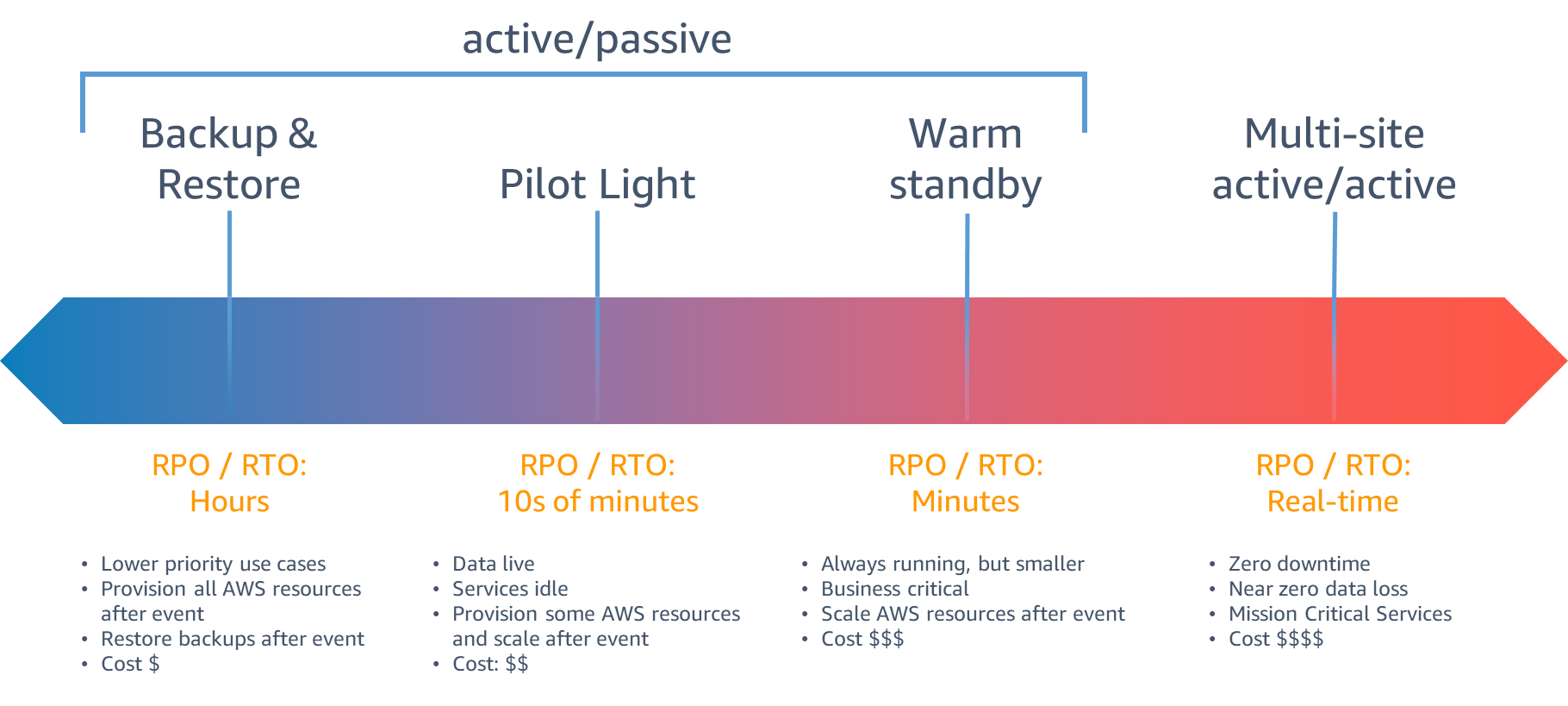
AWS offers resources and services to build a DR strategy that caters for your business needs. From left to right the image above shows how different DR strategies incur different RTO and RPO as well as the cost and operational complexity.
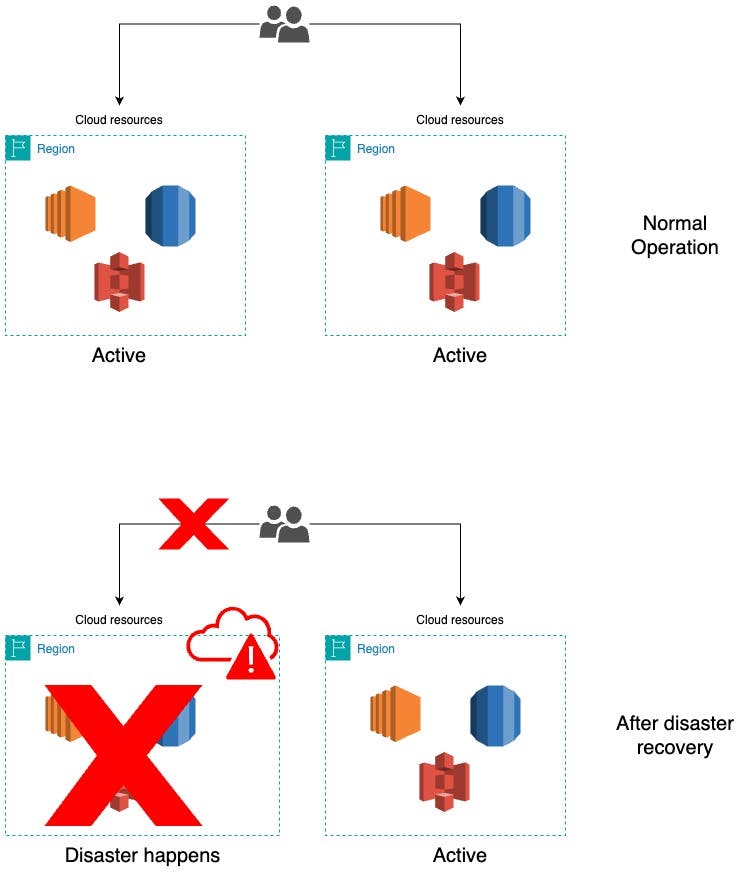
Active/Passive DR
"Active DR" typically refers to an active-active disaster recovery (DR) setup, which is a configuration where both the primary (production) and secondary (disaster recovery) environments are actively serving traffic simultaneously. This contrasts with the more traditional active-passive DR setup, where the secondary environment remains idle until it's needed for failover.
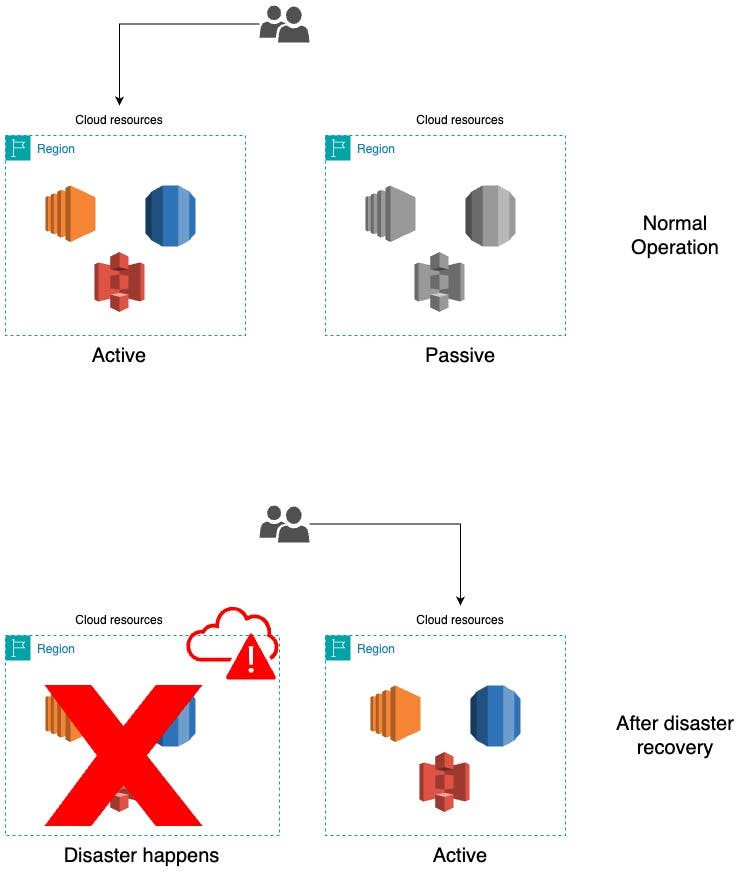
A "Passive DR" (Disaster Recovery) setup is a configuration where there is a primary (production) environment and a secondary environment that remains inactive until needed for recovery. In contrast to an active-active setup, where both environments are actively serving traffic simultaneously, in a passive DR scenario, the secondary environment typically remains on standby.
The Disaster Recovery pillar within the AWS Well-Architected Framework guides on building resilient and recoverable systems in the cloud. It emphasizes best practices related to resiliency, automation, security, and operational excellence to ensure that organizations can effectively respond to and recover from disruptions. Regular testing, automation, and adherence to AWS best practices contribute to a robust disaster recovery strategy.
In a nutshell, disaster recovery in AWS involves leveraging the global cloud infrastructure, implementing redundancy, automating processes, and prioritizing high availability. It's a comprehensive approach to ensure that organizations can recover quickly and maintain business continuity in the face of disruptions.